

Course Search Project
I worked with three other students to create a Course Search tool for the GenEd department. The premise for our project is “enterprise apps aren’t good”. Through utilizing what we donned “student first thinking” we created a tool that looks appealing and is easy to use. We later decided to pivot and create a business plan to market it to other institutions and later expand our product offerings to encompass more aspects of the Higher Ed app suite.
Through working on the course search I learned that it’s extremely difficult to establish a strong vision amongst a team. Though I still believe that the Steve Wozniaks of the world need to be championed and that by and large scientists and engineers should be glorified much more than C suite executives I’ve grown to appreciate the need for strong leaders like Steve Jobs.
Working on our prototype and finished product I got to learn a lot about natural language processing and, to a lesser degree, machine learning in general. We utilized R, Carrot and Apache’s OpenNLP to analyze the GenEd course inventory then create a data model to place courses in selected categories.
To learn more about our project and try a prototype, visit our project page.
Working at GenEd and Computer Services
My time working at GenEd and Computer Services has been pretty enjoyable. I’m a software developer in both roles. I started working at GenEd last Spring and just started at Computer Services in December. I plan on taking on a full time role at Computer Services after graduation.
At GenEd I’ve made a bunch of web apps, most notably https://gened.temple.edu/pexpassport, https://gened.temple.edu/course-search, and https://gened.temple.edu/api/course-review/ (requires Temple account). I also manage the server and database under the advisory of some people at computer services. By and large it runs pretty smoothly and the monitoring tool reports a little over 98% up-time. Not too bad.
At computer services lots of my work is either intangible or it’s on TUPortal, only accessible to users in a specific department. I’ve written utility code to contribute to what equates to the UI library and started writing/adapting shared SQL into a package for shared use / to reduce duplication across my pages and apps. Most recently I’ve been working on a drag and drop form builder to produce TUPortal style forms based on jQuery formBuilder.
Download Youtube Playlists [PHP Web App Tutorial]
I saw a friend downloading music from Youtube, pasting in each URL and downloading songs individually. I was like, “That’s ridiculous! Its taking too much time! Why don’t you just torrent if you’re going to do that?”. She was unwilling to venture to the Pirate’s bay so I decided to make a more convenient way to download mp3’s from YouTube.
This is pretty much just a web wrapper for dl-youtube and ffmpeg but interesting nonetheless. The real lesson here is interacting with the host system via PHP scripts.
It’s important to keep in mind that this was designed for personal (single user) use, it should be glaringly obvious that there would be bugs/incorrect behavior with concurrent usage and that this is totally unfit/unsafe for production.
This is what our final product will look like:

And while loading:
Here’s what the app does:
- Accepts a YouTube playlist URL
- Fetches the audio files in .m4a format
- Uses ffmpeg to convert them to .mp3
- Produces a .zip of the mp3’s
- Sends the zip to the user
- Deletes the files.
In order to make it work you’ll need:
- A web server
- PHP
- Python
- dl-youtube
- ffmpeg
You can get the code here.
First things first, install dl-youtube (On Linux, OS X):
$ sudo curl -L https://yt-dl.org/downloads/latest/youtube-dl -o /usr/local/bin/youtube-dl && chmod a+rx /usr/local/bin/youtube-dl
Next, install ffmpeg. Since I’m on OS X I used homebrew:
$ brew install ffmpeg
We’ll start off by making a directory within the web root and creating index.php
# If you're in /var/www/* or a directory owned by root or apache you may as well type
# $ sudo su
# and save yourself some trouble
$ mkdir downloadYoutube && cd downloadYoutube
$ touch index.php style.css
Now open the directory in your favorite text editor and let’s get coding.
I included Bootstrap and jQuery just to make things quicker but both are optional. Bootstrap is for styling and jQuery is a “write less do more” javaScript library. Neither of these libraries are necessary.
The homepage is really basic, just a form. Because of an inefficient parser there’s no quick way to post HTML so I’ll just post pictures. I typically hate this practice but, like I said, it’s unavoidable here.
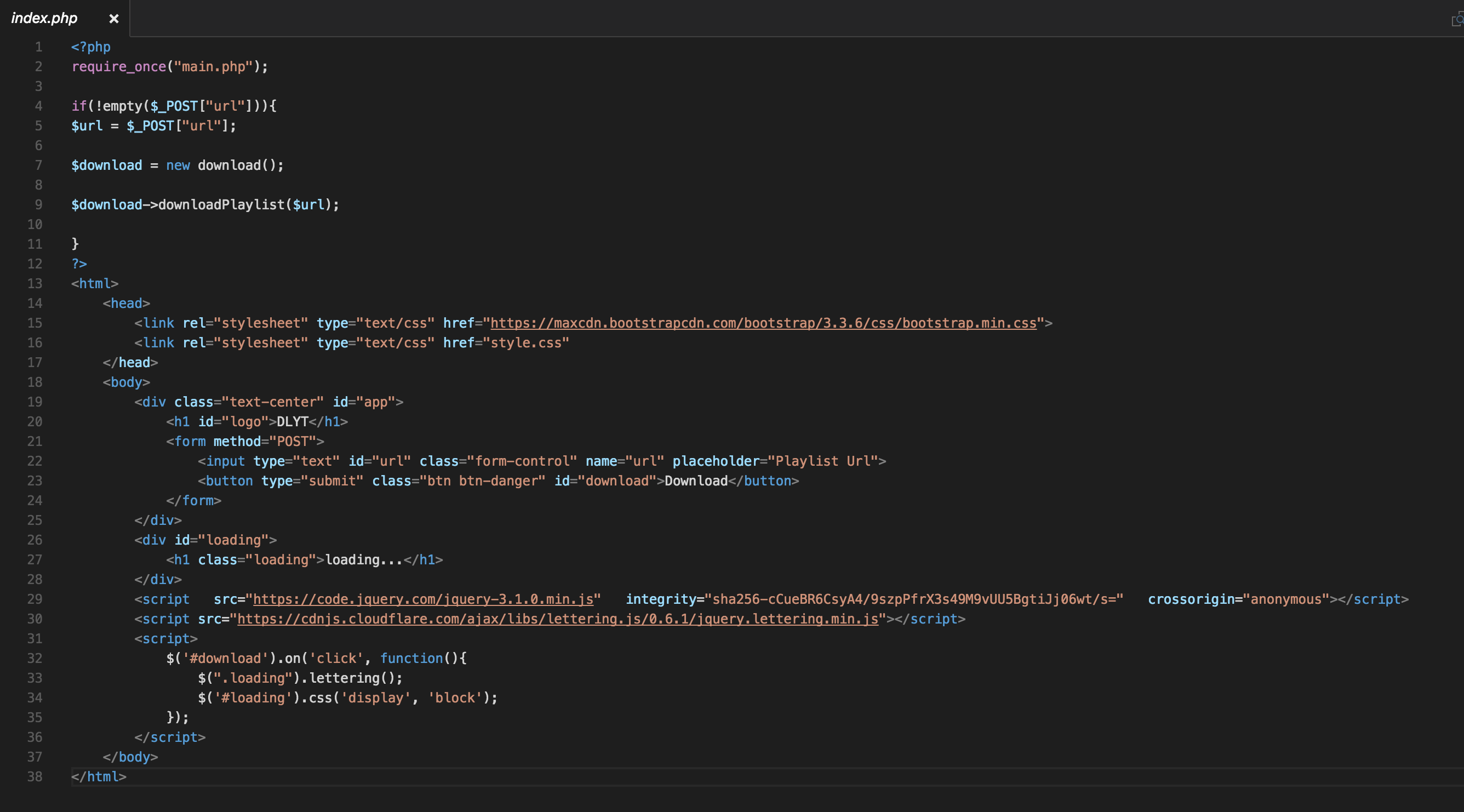
So as you can see, we require main.php at the top, and if the form is submitted, the script creates a new download object and calls the downloadPlaylist method which is passed the URL.
Once the download button is clicked/form is submitted jQuery unhides the loading message and the download begins.
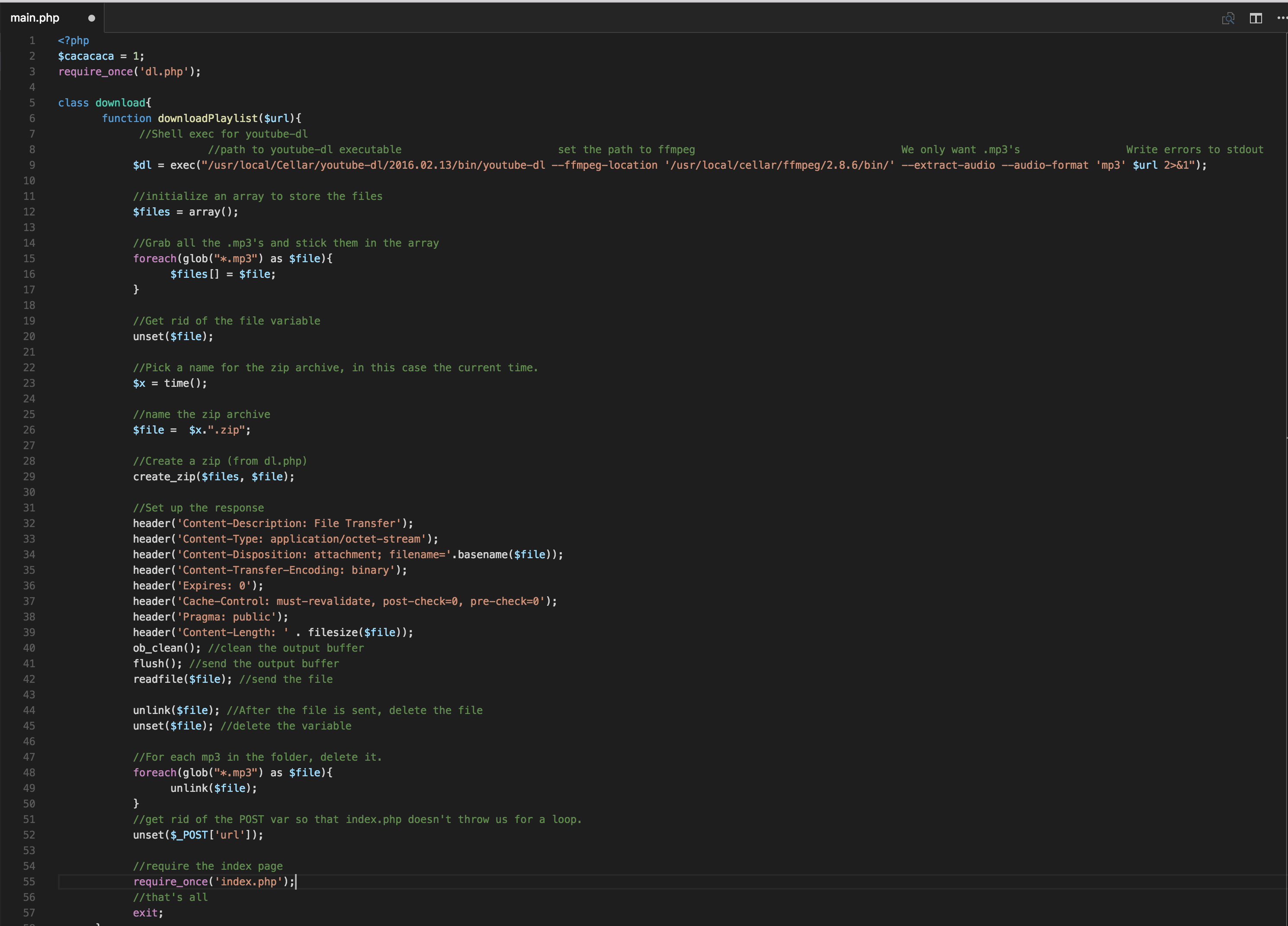
The bread and butter here is in a couple of different files, dl.php and main.php.
At the top we define a global variable so we can insure that dl.php isn’t accessed directly.
main.php interacts with ffmpeg and youtube-dl to get mp3’s, then passes them to dl.php to prep for download. Because brew only installs for the local user, PHP doesn’t have youtube-dl or ffmpeg in it’s path so I include the full path to the binaries. We only want mp3 files from the youtube videos, so we set those options.
#The command
$ 2>&1
#pipes output to stderr to stdout.
# 0 = stdin, 1 = stdout, 2= stderr
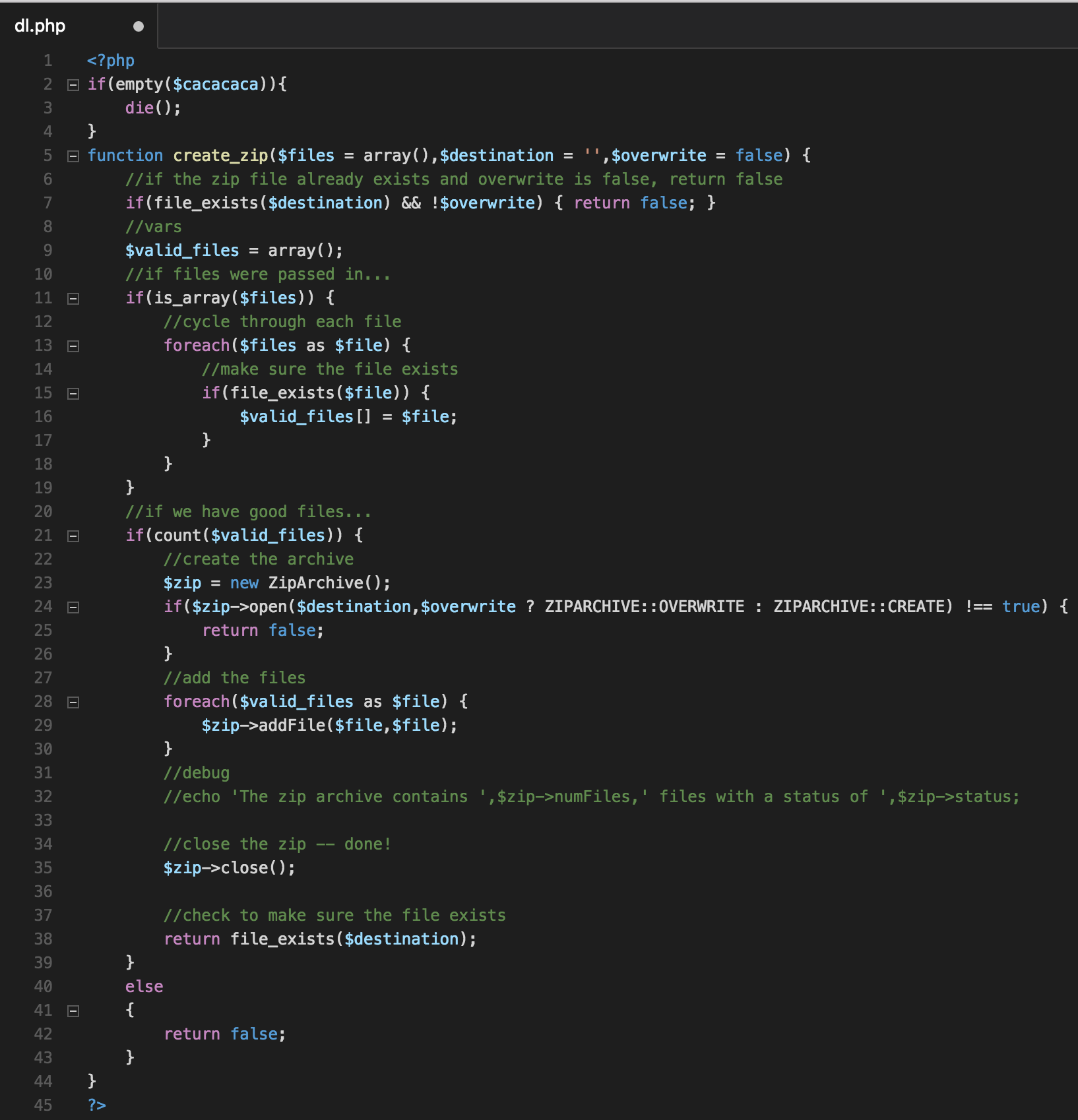
dl.php contains a script (or, a single function) for making a zip. It utilizes PHP’s ZipArchive class. The process is fairly straight forward, the function checks to make sure that the files passed exist, and that a zip can be created and saved. If the zip can be created, it is, and the function returns true. Otherwise, it returns false.
After everything’s all said and done, you should be able to download youtube playlists as a .zip with a simple web interface. No more ads, no more waiting.
Open Data: Temple
As a developer employed by Temple but outside of Computer Services resources are nil. Try searching for information pertaining to Shibboleth or CAS integration and you’ll find plenty of resources from Harvard, University of Oregon, etc. but nothing from Temple. Nearly everything that pertains to infrastructure seems to exist in a black box, as members of the Temple community students are essentially left to themselves when it comes to developing software to enrich our collective experience at the University.
Enough, I say! I’m of the opinion that information needs to be available to everyone, so let’s make it happen.
I have a post detailing a course information API, coming soon will be a guide to the TUMobile (TUPortal) API.
The goal is to build a (Node/PHP) wrapper for the API’s to allow easy integration with Temple services ushering in a new era for student-backed applications.
Hidden Temple Course Data Web API
I’m making a new app for the GenEd department to help students find GenEd courses that interest them. Before I could even start writing code I was at a major roadblock: I couldn’t find a way to get complete course info besides manually entering each course. That was, of course, until the discovery of Temple’s hidden (unadvertised?) web service.
bulletin.temple.edu hosts a cgi script: http://bulletin.temple.edu/ribbit/index.cgi that it sends AJAX calls to for tooltips in the course description page:


We can see in the inspector that the AJAX call takes 2 parameters: page and code.
![]()
The URL encoded string looks like this:
http://bulletin.temple.edu/ribbit/index.cgi?page=getcourse.rjs&code=MIS%202101
So, we can simply head to terminal and fire up curl to get some course descriptions:
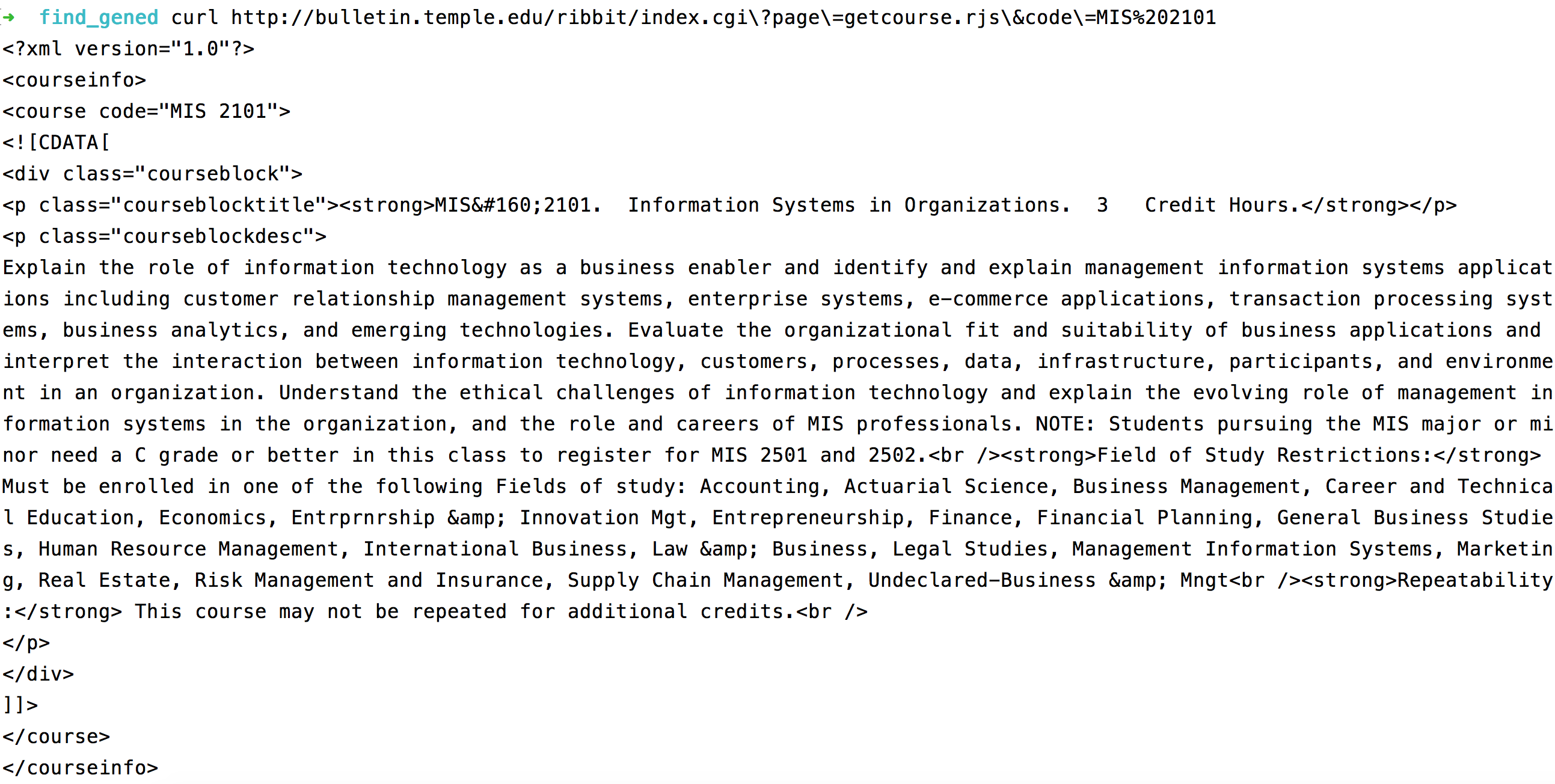
$ curl http://bulletin.temple.edu/ribbit/index.cgi?page=getcourse.rjs&code=MIS%202101
Unfortunately there’s no cross-origin support so you can’t replicate a solely client-side course search but you can get course info with a single line in PHP: echo file_get_contents(“http://bulletin.temple.edu/ribbit/index.cgi?page=getcourse.rjs&code=MIS%202101“);
Output:

Credit for the discovery of the CGI script goes to Temple Directory/IT Infrastructure guru Sam Yelman
For complete API documentation see https://github.com/betheluniversity/cascade/files/170046/CourseLeaf.-.Data.Access.APIs.pdf
Amerimax Summer Internship
This summer I had the opportunity to work at Amerimax in Lancaster, Pennsylvania. Amerimax manufactures home products. They have offices all around the country, in Canada and Europe. My first job function was to assist in their transition to Windows 7 and Microsoft Office 365. I also monitored the help desk and assisted users in both production and office environments.
When I started I was given several Windows XP machines. I upgraded their RAM and hard drives, used a PXE server to install Windows 7, transferred user data, installed specific programs and printers, and shipped it to a user. I would receive the user’s old computer and repeat the process.
The transition to Office 365 was a great learning experience. I got to experience first hand the issues you run into deploying new software across an enterprise. As we rolled out the software to different branches I spent days helping users who had incompatible software installed on their computer, people who somehow missed the SCCM deployment, and others who just weren’t sure how to use all of the new office features. I’ve also become quite familiar with Microsoft Office in the process.
Manning the service desk turned out to be an invaluable experience. Since there was production, shipping, sales, and customer service I had the chance to learn about technology in various environments. At the production and shipping end there were handheld scanners, label printers, and print servers that were frequently in need of service. Sales and customer service presented different challenges like using a large variety of different software with various levels of interaction.
Before working at Amerimax I considered myself a power user but home computer usage of any type can only prepare you so much for working to support an enterprise environment. I’m proud to say that I jumped right in and learned a lot about Microsoft System Center, IT infrastructure, and networking. With the help of knowledgable coworkers and online resources like Microsoft TechNet I was able to do my job very successfully.
I wish that I could have learned more about the business side of IT. I spoke with my coworkers about how and why we were transitioning to Windows 7 and Office 365 and learned a little about volume licensing and KMS but didn’t hear anything of decision making or reasoning.
I truly enjoyed working at Amerimax, As of 8/16 I’m about to begin my last week and I’ll really miss going to work everyday. My coworkers were personable and I really enjoyed the work. It was a great learning experience and I can without a doubt see myself working there in the future if the opportunity were to arise.